Tutorial de K-Means
Publiquei um novo notebook no Kaggle falando sobre algoritmos de clustering, especialmente o K-Means.
Ao longo do notebook, são abordados:
1. O que é K-Means, para que serve e como podemos utilizá-lo.
- Como funciona e o que é.
2. Problemas relacionados e métricas de comparação.
- Como avaliar um modelo no cenário não supervisionado?
3. Spectral Clustering
- Comparar o K-Means com outro algoritmo de clustering.
4. K-Means aplicado ao load_digits() (subconjunto do MNIST)
- Aplicar o K-Means no reconhecimento de dígitos e comparar com outros algoritmos de clustering
A ideia central do algoritmo K-Means é clusterização, ou seja, dado um dataset, conseguir separar os dados em clusters, de forma a diferenciá-los com labels diferentes. É um algoritmo não supervisionado, pois não necessita de um valor real ou classificação par construir os clusters.
Por exemplo, para um conjunto de dados distribuído como:
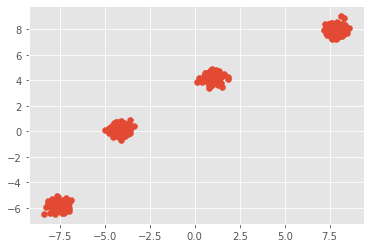 |
|---|
| Dataset obtidos da função make_blobs(), da biblioteca scikit-learn |
E aplicando o K-Means, chegamos na seguinte configuração de labels:
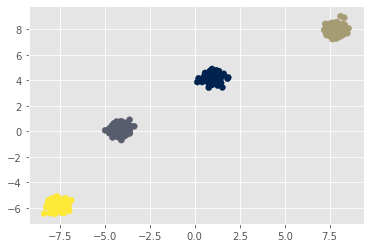 |
|---|
| Dataset com os labels obtidos pelo K-Means |
O algoritmo do K-Means é relativamente simples. Dado um número k de clusters inicial (veremos porque isso pode ser um problema) selecionados aleatoriamente, são calculados as distâncias de cada ponto aos k pontos (centros) escolhidos e o ponto recebe a label do cluster mais próximo, re-calculamos os centros com base na média do cluster, até que os clusters não mudem.
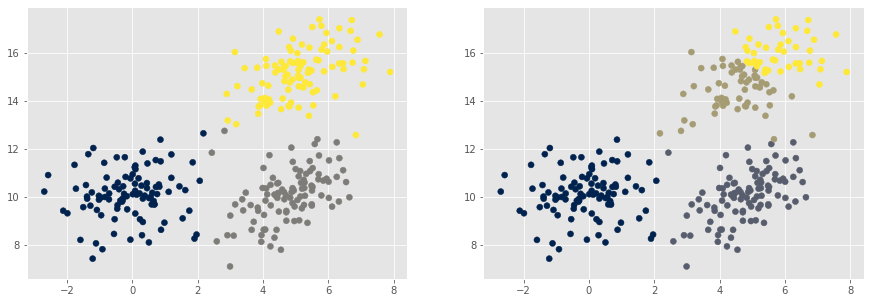 |
|---|
| Aplicação do K-Means com k=3 e k=4, em um dataset obtido de uma distribuição normal multivariada |
O notebook completo pode ser encontrado aqui!